
Задание
С помощью языка Python, машинного обучения и нейронных сетей провести анализ клиентской базы сервисной компании. За основу взять Амазон и СДЭК и провести соответствующий анализ. По компании СДЭК с помощью машинного обучения оценить степень удовлетворенности службой доставки. По компании Амазон проанализировать тональность отзывов, необходимо определить является ли отзыв положительным или отрицательным.
Функционал программы
Анализ удовлетворенности доставкой компании СДЭК и анализ тональности отзывов.
Содержание отчета к программе
1 ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ЯЗЫКА PYTHON И АНАЛИЗА ДАННЫХ.. 5
1.1 Язык программирования Python. 5
1.2 Понятие искусственного интеллекта. 11
1.3 Использование Python при работе с большими данными. 13
1.4 Краткая характеристика нейронных сетей. Разработка полносвязной нейронной сети. 16
2 ПРИМЕНЕНИЕ ТЕХНОЛОГИЙ BIG DATA, MACHINE LEARNING И НЕЙРОННЫХ СЕТЕЙ ДЛЯ АНАЛИЗА ДАННЫХ СЕРВИСНОЙ КОМПАНИИ.. 21
2.1 Понятие Big Data. 21
2.2 Постановка задачи. 22
2.3 Анализ клиентской базы СДЭК с применением технологий Big Data и Machine Learning. 23
2.4 Анализ тональности текста клиентских отзывов компании Amazon с применением технологий Big Data и нейронных сетей LSTM и GRU.. 33
ЗАКЛЮЧЕНИЕ. 47
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ. 49
Фрагмент программного кода
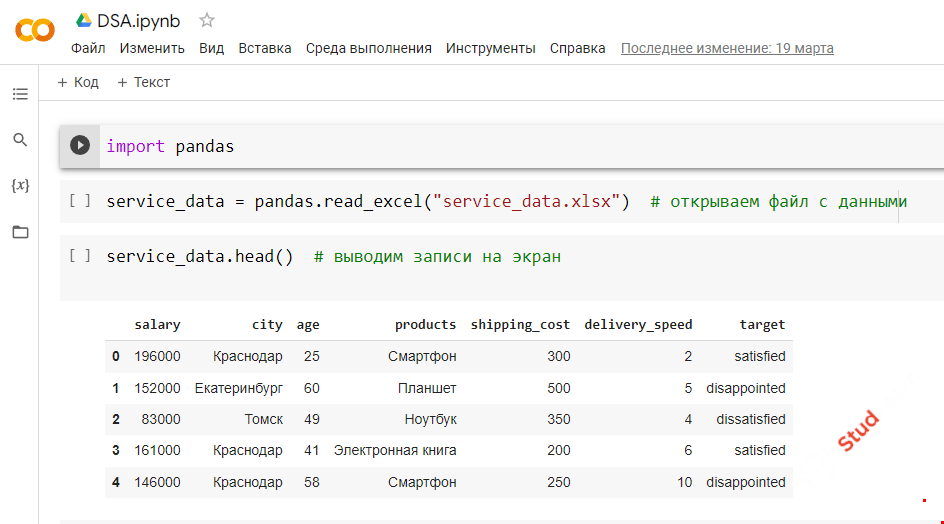
import pandas
service_data = pandas.read_excel("service_data.xlsx") # открываем файл с данными
service_data.head() # выводим записи на экран
service_data.salary.describe() # делаем выборку по зарплате
service_data.salary.hist() # Строим график по зарплате
service_data.age.hist() # Строим график по возрасту
service_data.city.value_counts().plot(kind='barh')
service_data.shipping_cost.value_counts().plot(kind='bar')
service_data.delivery_speed.value_counts().plot(kind='barh')
final_data = pandas.get_dummies(service_data, columns=['city', 'products', 'shipping_cost', 'delivery_speed'])
final_data
X = final_data.drop('target', axis=1) # Данные на основе которых мы построим прогноз
y = final_data.target # Данные, которые мы хотим спрогнозировать
from sklearn.ensemble import BaggingClassifier
y.value_counts()
forest = BaggingClassifier() # можно указывать настройки модели
forest.fit(X, y) # обучаем модель
X.head(1) # выводим данные
{col:[0] for col in X.columns} # добавляем данные в список
example = {'salary': [190000],
'age': [25],
'city_Екатеринбург': [0],
'city_Киев': [0],
'city_Краснодар': [0],
'city_Минск': [0],
'city_Москва': [0],
'city_Новосибирск': [0],
'city_Омск': [0],
'city_Петербург': [1],
'city_Томск': [0],
'city_Хабаровск': [0],
'city_Ярославль': [0],
'products_Ноутбук': [1],
'products_Планшет': [1],
'products_Смартфон': [0],
'products_Электронная книга': [1],
'shipping_cost_200': [0],
'shipping_cost_250': [0],
'shipping_cost_300': [0],
'shipping_cost_350': [0],
'shipping_cost_500': [1],
'delivery_speed_2': [0],
'delivery_speed_4': [0],
'delivery_speed_5': [0],
'delivery_speed_6': [0],
'delivery_speed_10': [1]}
example_df = pandas.DataFrame(example)
forest.predict(example_df) # проанализировали степень удовлетворенности клиентов
forest.predict_proba(example_df)
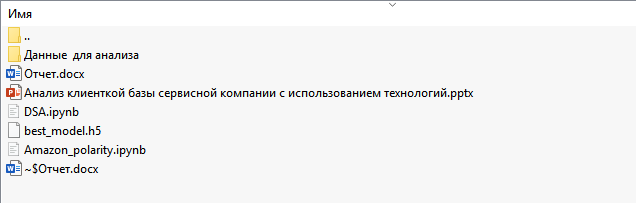
Скриншот архива с проектом
Пояснения по запуску программы
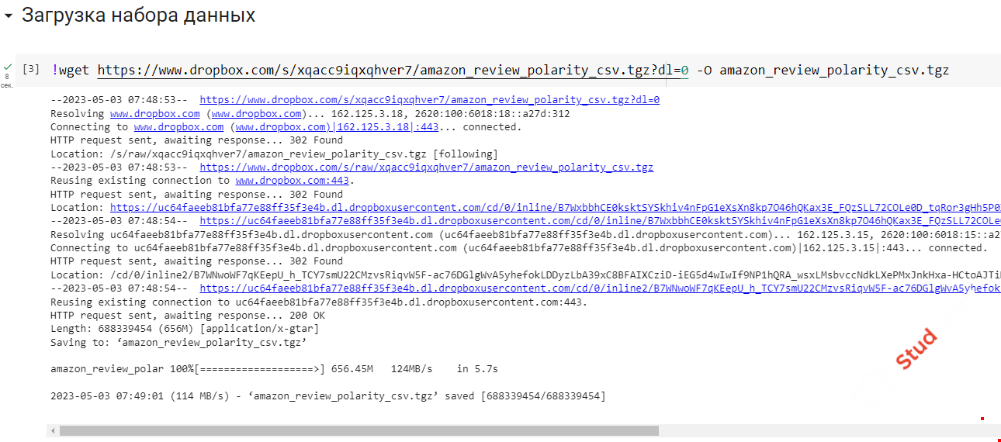
Тут все просто как апельсин. Открываем Google Colab, загружаем файлы блокнота, открываем файл DSA и подключаем виртуальную среду выполнения, загружаем файл Excel, запускаем ячейки и смотрим на результат, при необходимости меняем параметры модели, и повторяем процедуру, смотрим на результат. То же самое с файлом Amazon, но предворительно необходимо скачать архив с моего DrobBox загрузить на свой и поменять ссылку в блокноте Google Colab. После чего запустить по очереди каждую ячейку , посмотреть на результат работы нейронной сети. При необходимости изменить текст собственного отзыва, чтобы первый например стал отрицательным а второй положительным.

-