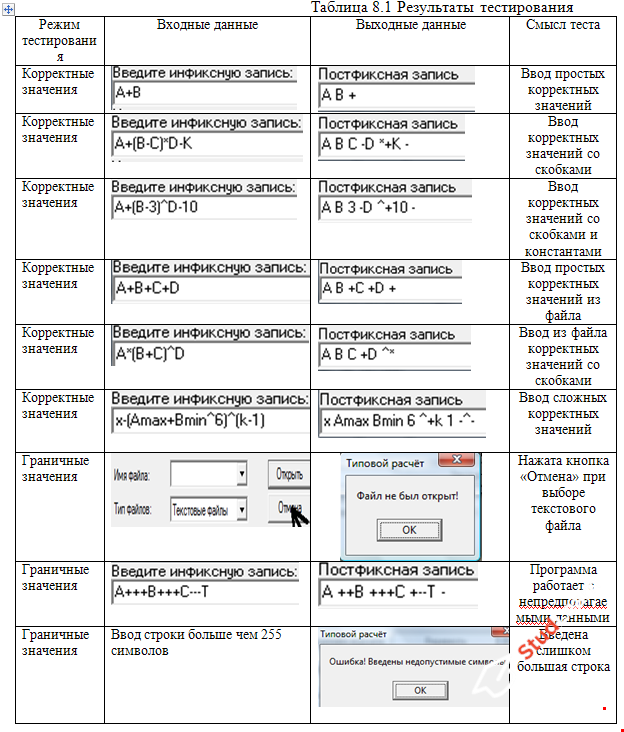
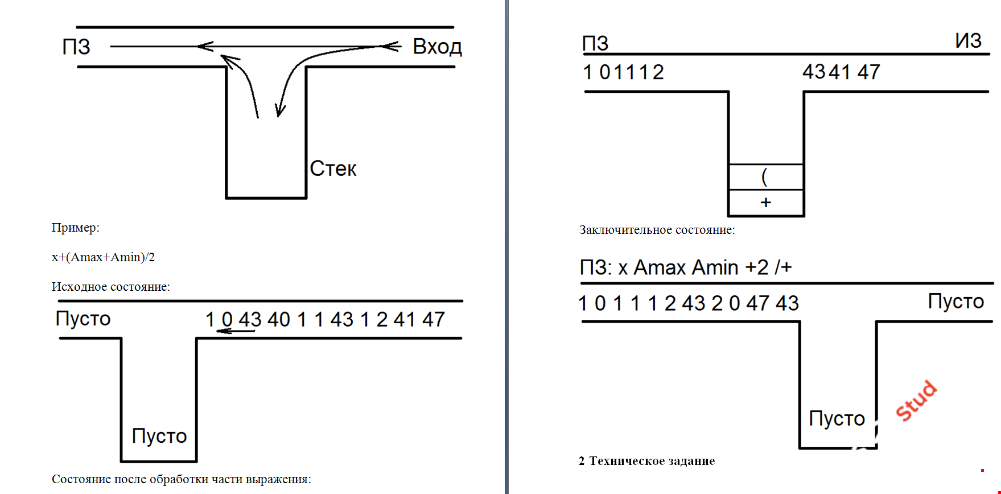
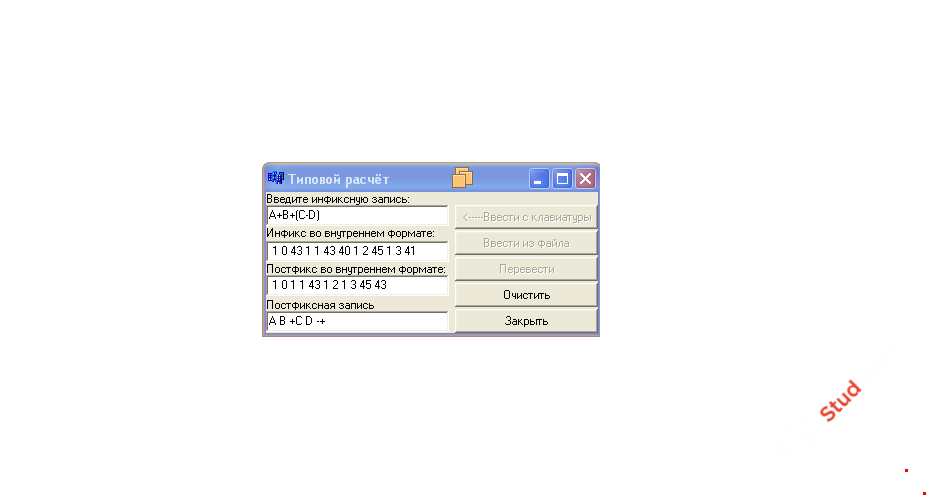
Алгоритм перевода в постфиксную запись с помощью стека (алгоритм Дейкстры)
Лексемы выражения, записанного в инфиксной форме, последовательно просматриваются слева направо.
- Если класс очередной лексемы VAR или NUMB, то такая же лексема присваивается к постфиксной записи выражения.
- Если очередная входная лексема является скобкой «(», то она добавляется в верхушку стека.
- Если очередная входная лексема является знаком операции +,-,*,/, то проверяется верхний элемент стека:
а). если верхним в стеке является скобка «(», то входная лексема записывается в стек и читается следующая лексема.
б). если верхним в стеке является знак операции, приоритет которой выше или равен приоритету входной операции, то операция из верхушки стека выталкивается и приписывается к формируемой постфиксной записи (входной символ при этом не изменяется).
- Если очередная входная лексема является закрывающей скобкой «)», то операции из стека последовательно выталкиваются и приписываются к формируемой постфиксной записи до тех пор, пока верхней в стеке не окажется соответствующая открывающая скобка. После этого скобки «взаимно удаляются», т.е. открывающая скобка просто выталкивается из стека и читается следующая входная лексема.
Если в процессе выталкивания операций из стека по закрывающей скобке происходит опустошение стека и соответствующая открывающая скобка в стеке не обнаружится, то выводится сообщение об ошибке (нарушен баланс скобок).
Процесс продолжается до исчерпания входного выражения, т.е. до обнаружения лексемы «EndOfL» после обнаружения EndOfL выполняется выталкивание операций из стека и их приписывание (добавление) к выходной постфиксной записи до опустошения стека.
Если в процессе выталкивания операций из стека по EndOfL в верхушке стека обнаруживается открывающая скобка, то выводится сообщение об ошибке (нарушен баланс скобок).
Пример кода:
//---------------------------------------------------------------------------
//процедура перевода строки в Infix
void StrToInfix(char str[nmax], unsigned int Inf[nmax], char VectorP [20][6],char VectorC [20][6],bool *err)
{
int i=0;
int k=0; int kk=0; int m=0;
while ((str[i]!='\0')&(*err)) //проверяем строку на допустимые символы
{if ((!isalpha(str[i]))&(!isdigit(str[i]))&(!isdelm(str[i]))&(str[i]!=' '))
{*err=false;}i++;
}
i=0; //error==true ошибок нет
while ((str[i]!='\0')&(*err)) //пока не конец строки и нет ошибок
{
while (str[i]==' '){i++;}//пропускаем пробелы
int j=0;
if (isalpha(str[i])) //if переменная
{
j=0;
while ((isalpha(str[i]))||(isdigit(str[i])))//если обнаружили переменную
{VectorP[k][j]=str[i];j++; i++;}//пишем её в массив переменных
Inf[m]=1; Inf[m+1]=k; m++; m++; i--;//добавляем в инфикс коды этой переменной
VectorP[k][j]='\0'; j++;//дописываем символ конца строки
k++;//увеличиваем индекс, определяющий в какую строку массива переменных нужно писать п.
}
else//если не переменная
{ if (isdigit(str[i]))//если цифра
{ j=0;
while (isdigit(str[i]))//пока цифра
{VectorC[kk][j]=str[i]; i++; j++;}//пишем её в массив чисел
Inf[m]=2; Inf[m+1]=kk; m++; m++; i--;//добавляем в инфикс коды этого числа
VectorC[kk][j]='\0'; j++;//дописываем символ конца строки
kk++;//увеличиваем индекс, определяющий в какую строку массива чисел нужно писать ч.
}
else//если не цифра
{if (isdelm(str[i]))//если разделитель
{
if (str[i]=='(') {Inf[m]=40; m++;}//пишем соответствующие коды
else
{
if (str[i]==')') {Inf[m]=41; m++;}
else
{
if (str[i]=='+') {Inf[m]=43; m++;}
else
{
if (str[i]=='-') {Inf[m]=45; m++;} //также можно использовать
else
{
if (str[i]=='*') {Inf[m]=42; m++;} //switch-case
else
{
if (str[i]=='/') {Inf[m]=47; m++;}
else
{
if (str[i]=='^') {Inf[m]=94; m++;}
}
}
}
}
}
}
}
}//если не цифра
}//если не переменная
Inf[m]=255;//приписываем крод конца строки
i++;
}
}
Содержание архива:
- исходный код на Borland C++
- пояснительная записка к курсовой работе (18 страниц)

-