Задание
Лабораторную работу примера кластеризации я решил делать в Anaconda (это дистрибутив Python и R вместе с основными библиотеками для анализа данных и пакетным менеджером conda) с помощью инструмента Jupyter Notebook.
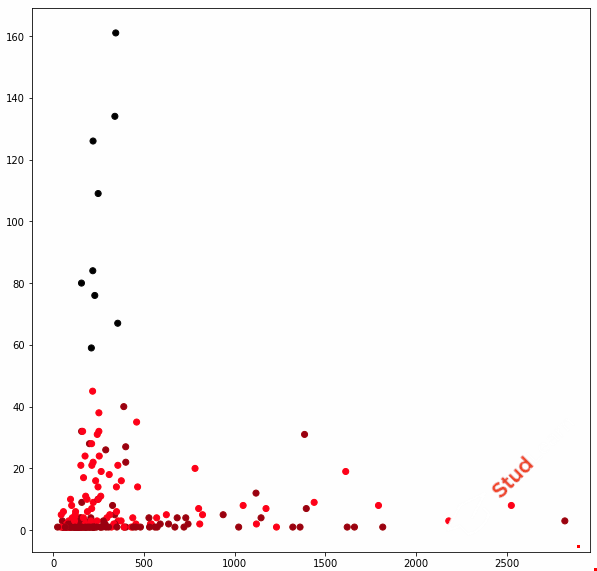
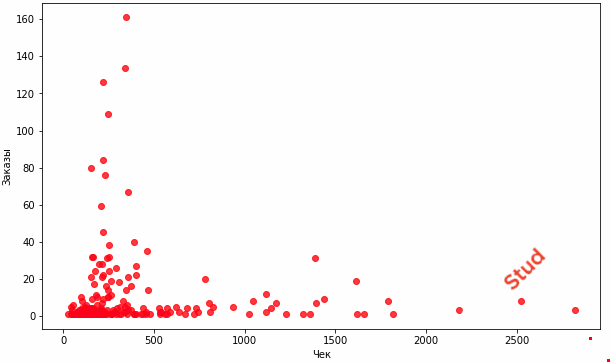
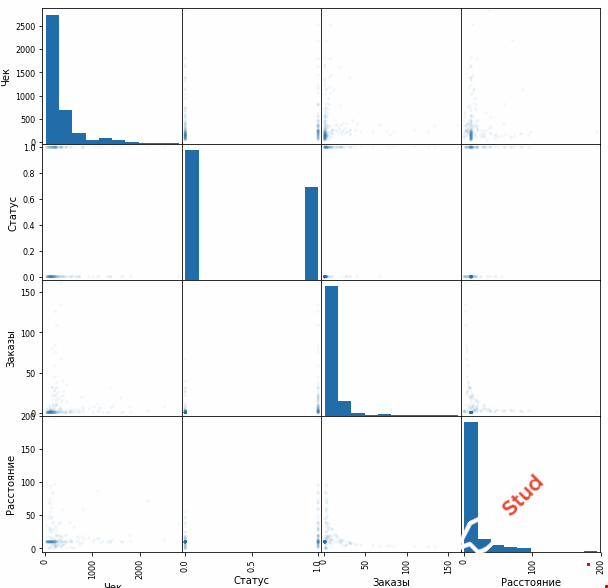
Данный скрипт позволяет выполнить кластеризацию методом k-средних. Для выполнения кластеризации мы используем Excel-файл, который содержит таблицу
Фрагмент программного кода
def fancy_dendrogram(*args, **kwargs):
max_d = kwargs.pop('max_d', None)
if max_d and 'color_threshold' not in kwargs:
kwargs['color_threshold'] = max_d
annotate_above = kwargs.pop('annotate_above', 0)
ddata = dendrogram(*args, **kwargs)
if not kwargs.get('no_plot', False):
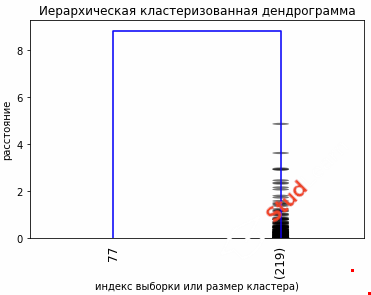
plt.title('Иерархическая кластеризованная дендрограмма')
plt.xlabel('индекс выборки или (размер кластера)')
plt.ylabel('расстояние')
for i, d, c in zip(ddata['icoord'], ddata['dcoord'], ddata['color_list']):
x = 0.5 * sum(i[1:3])
y = d[1]
if y > annotate_above:
plt.plot(x, y, 'o', c=c)
plt.annotate("%.3g" % y, (x, y), xytext=(0, -5),
textcoords='offset points',
va='top', ha='center')
if max_d:
plt.axhline(y=max_d, c='k')
return ddata
Скриншот архива с проектом

-