
При использовании байесовской классификации текстовый документ представляется как набор слов (термов), вероятности которых условно не зависят друг от друга. По причине независимости термов байесовскую классификацию называют также наивной.
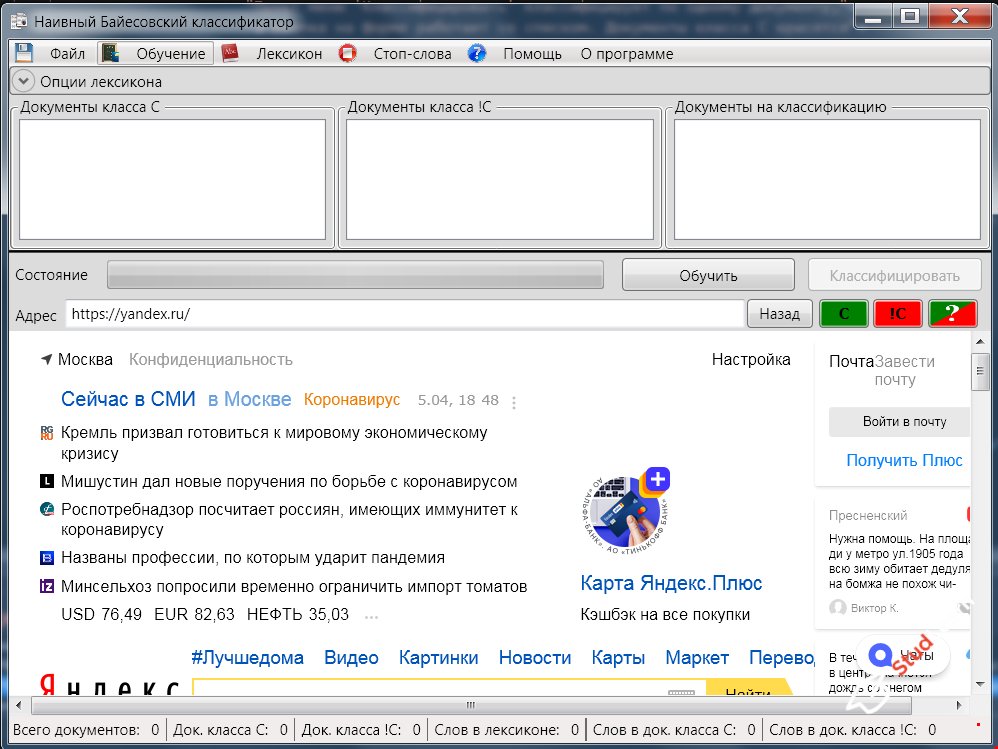
Для программной реализации использовался ЯВУ С# и Net Framework 4. Программа позволяет провести обучение и эксплуатацию обученного классификатора, как для обычных текстовых документов, так и для веб-страниц в интернете.
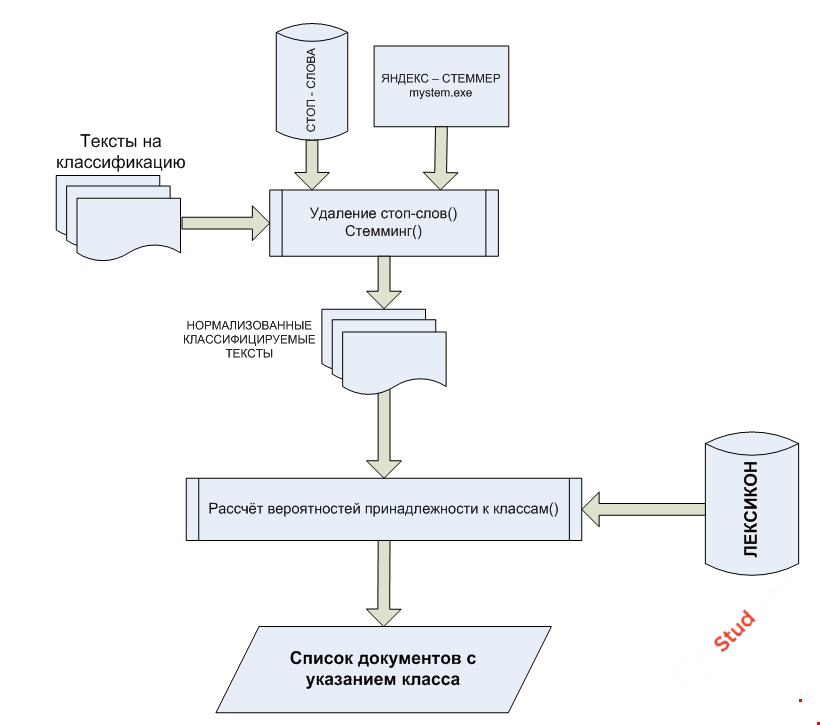
Все документы, проходят одинаковую предварительную обработку, в процессе которой они приводятся к модели «bag of words» [1,3]. В процессе предварительной обработки из текста удаляются знаки препинания, пробелы, английские слова и, в случае веб-страниц, HTML и JavaScript теги. После того, как в документе остаются только слова, они приводятся к нормальному виду с помощью стеммера от Яндекса[4].
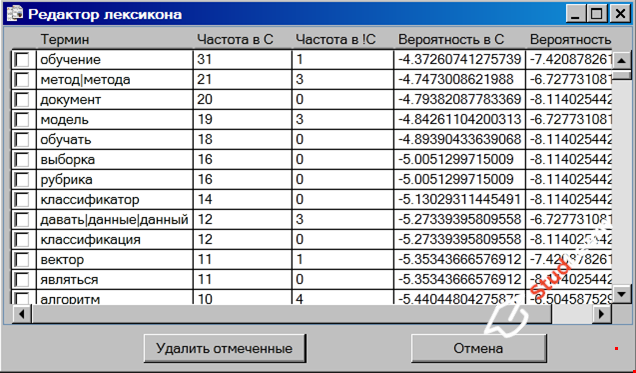
На этапе обучения программа на основе обучающей выборки вычисляет частотные характеристики терминов и величины, используемые в формулах (2) и (3).
Во время обучения у пользователя есть возможность отбора терминов с тем, чтобы сократить размер словаря и снизить влияние «шумовых» терминов. Это можно делать вручную или автоматически на основе известного критерия tf-idf[1].
На этапе классификации после указанной выше обработки входного документа к его терминам применяются статистические характеристики, полученные на этапе обучения и, в конечном счете, вычисляются все величины, используемые в решающей функции (2).
Программа на C#+WPF
Пример кода:
/// <summary>
/// Сокращает лексикон.
/// </summary>
/// <param name="kC">Количество терминов класса С.</param>
/// <param name="kNC">Количество терминов класса !С.</param>
/// <returns>Сокращённый лексикон.</returns>
public Lexicon ReduceLexicon(int kC, int kNC)
{
//сортировка лексикона с анонимным методом
this.Sort(delegate(Term term1, Term term2){
return term2.CDocCount.CompareTo(term1.CDocCount);
});
//ввод количества признаков
Lexicon BufLex = new Lexicon(this);
if (this.Count > kC){ //если длина лексикона позволяет проводить сокращение
for (int i = 0; i < kC; i++){
BufLex.Add(this[i]);
}
}
if (this.Count > kNC){
//теперь отсортируем список по убыванию NCDocCount
this.Sort(delegate(Term term1, Term term2){
return term2.NCDocCount.CompareTo(term1.NCDocCount);
});
for (int i = 0; i < kNC; i++){
if (!BufLex.Contains(this[i])){
BufLex.Add(this[i]);
}
}
}
return BufLex;
}
Содержание архива:
- исходный код на C# для Visual Studio
- пояснительная записка к курсовой работе (25 страниц)

-